![]()
最適な練習法にはDatabricks Databricks-Machine-Learning-Associate問題集で素晴らしいDatabricks-Machine-Learning-Associate試験問題PDF
更新された検証済みの合格させるDatabricks-Machine-Learning-Associate試験リアル問題と解答
質問 # 33
A data scientist is developing a single-node machine learning model. They have a large number of model configurations to test as a part of their experiment. As a result, the model tuning process takes too long to complete. Which of the following approaches can be used to speed up the model tuning process?
- A. Scale up with Spark ML
- B. Implement MLflow Experiment Tracking
- C. Enable autoscaling clusters
- D. Parallelize with Hyperopt
正解:D
解説:
To speed up the model tuning process when dealing with a large number of model configurations, parallelizing the hyperparameter search using Hyperopt is an effective approach. Hyperopt provides tools like SparkTrials which can run hyperparameter optimization in parallel across a Spark cluster.
Example:
from hyperopt import fmin, tpe, hp, SparkTrials search_space = { 'x': hp.uniform('x', 0, 1), 'y': hp.uniform('y', 0, 1) } def objective(params): return params['x'] ** 2 + params['y'] ** 2 spark_trials = SparkTrials(parallelism=4) best = fmin(fn=objective, space=search_space, algo=tpe.suggest, max_evals=100, trials=spark_trials) Reference:
Hyperopt Documentation
質問 # 34
A machine learning engineer is trying to scale a machine learning pipeline pipeline that contains multiple feature engineering stages and a modeling stage. As part of the cross-validation process, they are using the following code block: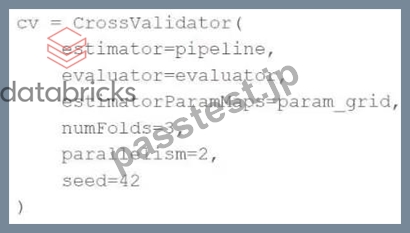
A colleague suggests that the code block can be changed to speed up the tuning process by passing the model object to the estimator parameter and then placing the updated cv object as the final stage of the pipeline in place of the original model.
Which of the following is a negative consequence of the approach suggested by the colleague?
- A. The cross-validation process will no longer be reproducible
- B. The feature engineering stages will be computed using validation data
- C. The cross-validation process will no longer be
- D. The model will be refit one more per cross-validation fold
- E. The model will take longer to train for each unique combination of hvperparameter values
正解:B
解説:
If the model object is passed to the estimator parameter of CrossValidator and the cross-validation object itself is placed as a stage in the pipeline, the feature engineering stages within the pipeline would be applied separately to each training and validation fold during cross-validation. This leads to a significant issue: the feature engineering stages would be computed using validation data, thereby leaking information from the validation set into the training process. This would potentially invalidate the cross-validation results by giving an overly optimistic performance estimate.
Reference:
Cross-validation and Pipeline Integration in MLlib (Avoiding Data Leakage in Pipelines).
質問 # 35
A data scientist is developing a machine learning pipeline using AutoML on Databricks Machine Learning.
Which of the following steps will the data scientist need to perform outside of their AutoML experiment?
- A. Model deployment
- B. Exploratory data analysis
- C. Model tuning
- D. Model evaluation
正解:B
解説:
AutoML platforms, such as the one available in Databricks Machine Learning, streamline various stages of the machine learning pipeline including feature engineering, model selection, hyperparameter tuning, and model evaluation. However, exploratory data analysis (EDA) is typically performed outside the AutoML process. EDA involves understanding the dataset, visualizing distributions, identifying anomalies, and gaining insights into data before feeding it into a machine learning pipeline. This step is crucial for ensuring that the data is clean and suitable for model training but is generally done manually by the data scientist.
Reference
Databricks documentation on AutoML: https://docs.databricks.com/applications/machine-learning/automl.html
質問 # 36
An organization is developing a feature repository and is electing to one-hot encode all categorical feature variables. A data scientist suggests that the categorical feature variables should not be one-hot encoded within the feature repository.
Which of the following explanations justifies this suggestion?
- A. One-hot encoding is dependent on the target variable's values which differ for each application.
- B. One-hot encoding is computationally intensive and should only be performed on small samples of training sets for individual machine learning problems.
- C. One-hot encoding is not a common strategy for representing categorical feature variables numerically.
- D. One-hot encoding is a potentially problematic categorical variable strategy for some machine learning algorithms.
- E. One-hot encoding is not supported by most machine learning libraries.
正解:D
解説:
One-hot encoding transforms categorical variables into a format that can be provided to machine learning algorithms to better predict the output. However, when done prematurely or universally within a feature repository, it can be problematic:
Dimensionality Increase: One-hot encoding significantly increases the feature space, especially with high cardinality features, which can lead to high memory consumption and slower computation.
Model Specificity: Some models handle categorical variables natively (like decision trees and boosting algorithms), and premature one-hot encoding can lead to inefficiency and loss of information (e.g., ordinal relationships).
Sparse Matrix Issue: It often results in a sparse matrix where most values are zero, which can be inefficient in both storage and computation for some algorithms.
Generalization vs. Specificity: Encoding should ideally be tailored to specific models and use cases rather than applied generally in a feature repository.
Reference
"Feature Engineering and Selection: A Practical Approach for Predictive Models" by Max Kuhn and Kjell Johnson (CRC Press, 2019).
質問 # 37
A machine learning engineer has been notified that a new Staging version of a model registered to the MLflow Model Registry has passed all tests. As a result, the machine learning engineer wants to put this model into production by transitioning it to the Production stage in the Model Registry.
From which of the following pages in Databricks Machine Learning can the machine learning engineer accomplish this task?
- A. The experiment page in the Experiments observatory
- B. The model version page in the MLflow Model Registry
- C. The home page of the MLflow Model Registry
- D. The model page in the MLflow Model Registry
正解:B
解説:
The machine learning engineer can transition a model version to the Production stage in the Model Registry from the model version page. This page provides detailed information about a specific version of a model, including its metrics, parameters, and current stage. From here, the engineer can perform stage transitions, moving the model from Staging to Production after it has passed all necessary tests.
Reference
Databricks documentation on MLflow Model Registry: https://docs.databricks.com/applications/mlflow/model-registry.html#model-version
質問 # 38
A data scientist has developed a linear regression model using Spark ML and computed the predictions in a Spark DataFrame preds_df with the following schema:
prediction DOUBLE
actual DOUBLE
Which of the following code blocks can be used to compute the root mean-squared-error of the model according to the data in preds_df and assign it to the rmse variable?
- A.

- B.

- C.

- D.

正解:D
解説:
To compute the root mean-squared-error (RMSE) of a linear regression model using Spark ML, the RegressionEvaluator class is used. The RegressionEvaluator is specifically designed for regression tasks and can calculate various metrics, including RMSE, based on the columns containing predictions and actual values.
The correct code block to compute RMSE from the preds_df DataFrame is:
regression_evaluator = RegressionEvaluator( predictionCol="prediction", labelCol="actual", metricName="rmse" ) rmse = regression_evaluator.evaluate(preds_df) This code creates an instance of RegressionEvaluator, specifying the prediction and label columns, as well as the metric to be computed ("rmse"). It then evaluates the predictions in preds_df and assigns the resulting RMSE value to the rmse variable.
Options A and B incorrectly use BinaryClassificationEvaluator, which is not suitable for regression tasks. Option D also incorrectly uses BinaryClassificationEvaluator.
Reference:
PySpark ML Documentation
質問 # 39
A data scientist has created two linear regression models. The first model uses price as a label variable and the second model uses log(price) as a label variable. When evaluating the RMSE of each model by comparing the label predictions to the actual price values, the data scientist notices that the RMSE for the second model is much larger than the RMSE of the first model.
Which of the following possible explanations for this difference is invalid?
- A. The data scientist failed to exponentiate the predictions in the second model prior to computing the RMSE
- B. The first model is much more accurate than the second model
- C. The second model is much more accurate than the first model
- D. The data scientist failed to take the log of the predictions in the first model prior to computing the RMSE
- E. The RMSE is an invalid evaluation metric for regression problems
正解:E
解説:
The Root Mean Squared Error (RMSE) is a standard and widely used metric for evaluating the accuracy of regression models. The statement that it is invalid is incorrect. Here's a breakdown of why the other statements are or are not valid:
Transformations and RMSE Calculation: If the model predictions were transformed (e.g., using log), they should be converted back to their original scale before calculating RMSE to ensure accuracy in the evaluation. Missteps in this conversion process can lead to misleading RMSE values.
Accuracy of Models: Without additional information, we can't definitively say which model is more accurate without considering their RMSE values properly scaled back to the original price scale.
Appropriateness of RMSE: RMSE is entirely valid for regression problems as it provides a measure of how accurately a model predicts the outcome, expressed in the same units as the dependent variable.
Reference
"Applied Predictive Modeling" by Max Kuhn and Kjell Johnson (Springer, 2013), particularly the chapters discussing model evaluation metrics.
質問 # 40
The implementation of linear regression in Spark ML first attempts to solve the linear regression problem using matrix decomposition, but this method does not scale well to large datasets with a large number of variables.
Which of the following approaches does Spark ML use to distribute the training of a linear regression model for large data?
- A. Least-squares method
- B. Logistic regression
- C. Iterative optimization
- D. Singular value decomposition
- E. Spark ML cannot distribute linear regression training
正解:C
解説:
For large datasets with many variables, Spark ML distributes the training of a linear regression model using iterative optimization methods. Specifically, Spark ML employs algorithms such as Gradient Descent or L-BFGS (Limited-memory Broyden-Fletcher-Goldfarb-Shanno) to iteratively minimize the loss function. These iterative methods are suitable for distributed computing environments and can handle large-scale data efficiently by partitioning the data across nodes in a cluster and performing parallel updates.
Reference:
Spark MLlib Documentation (Linear Regression with Iterative Optimization).
質問 # 41
Which of the following machine learning algorithms typically uses bagging?
- A. Linear regression
- B. Gradient boosted trees
- C. Decision tree
- D. Random forest
- E. K-means
正解:D
解説:
Random Forest is a machine learning algorithm that typically uses bagging (Bootstrap Aggregating). Bagging involves training multiple models independently on different random subsets of the data and then combining their predictions. Random Forests consist of many decision trees trained on random subsets of the training data and features, and their predictions are averaged to improve accuracy and control overfitting. This method enhances model robustness and predictive performance.
Reference:
Ensemble Methods in Machine Learning (Understanding Bagging and Random Forests).
質問 # 42
A machine learning engineer has grown tired of needing to install the MLflow Python library on each of their clusters. They ask a senior machine learning engineer how their notebooks can load the MLflow library without installing it each time. The senior machine learning engineer suggests that they use Databricks Runtime for Machine Learning.
Which of the following approaches describes how the machine learning engineer can begin using Databricks Runtime for Machine Learning?
- A. They can select a Databricks Runtime ML version from the Databricks Runtime Version dropdown when creating their clusters.
- B. They can set the runtime-version variable in their Spark session to "ml".
- C. They can add a line enabling Databricks Runtime ML in their init script when creating their clusters.
- D. They can check the Databricks Runtime ML box when creating their clusters.
正解:A
解説:
The Databricks Runtime for Machine Learning includes pre-installed packages and libraries essential for machine learning and deep learning, including MLflow. To use it, the machine learning engineer can simply select an appropriate Databricks Runtime ML version from the "Databricks Runtime Version" dropdown menu while creating their cluster. This selection ensures that all necessary machine learning libraries, including MLflow, are pre-installed and ready for use, avoiding the need to manually install them each time.
Reference
Databricks documentation on creating clusters: https://docs.databricks.com/clusters/create.html
質問 # 43
A data scientist is wanting to explore the Spark DataFrame spark_df. The data scientist wants visual histograms displaying the distribution of numeric features to be included in the exploration.
Which of the following lines of code can the data scientist run to accomplish the task?
- A. dbutils.data(spark_df).summarize()
- B. spark_df.describe()
- C. This task cannot be accomplished in a single line of code.
- D. spark_df.summary()
- E. dbutils.data.summarize (spark_df)
正解:E
解説:
To display visual histograms and summaries of the numeric features in a Spark DataFrame, the Databricks utility function dbutils.data.summarize can be used. This function provides a comprehensive summary, including visual histograms.
Correct code:
dbutils.data.summarize(spark_df)
Other options like spark_df.describe() and spark_df.summary() provide textual statistical summaries but do not include visual histograms.
Reference:
Databricks Utilities Documentation
質問 # 44
A data scientist is attempting to tune a logistic regression model logistic using scikit-learn. They want to specify a search space for two hyperparameters and let the tuning process randomly select values for each evaluation.
They attempt to run the following code block, but it does not accomplish the desired task:
Which of the following changes can the data scientist make to accomplish the task?
- A. Replace the GridSearchCV operation with RandomizedSearchCV
- B. Replace the random_state=0 argument with random_state=1
- C. Replace the GridSearchCV operation with cross_validate
- D. Replace the GridSearchCV operation with ParameterGrid
- E. Replace the penalty= ['12', '11'] argument with penalty=uniform ('12', '11')
正解:A
解説:
The user wants to specify a search space for hyperparameters and let the tuning process randomly select values. GridSearchCV systematically tries every combination of the provided hyperparameter values, which can be computationally expensive and time-consuming. RandomizedSearchCV, on the other hand, samples hyperparameters from a distribution for a fixed number of iterations. This approach is usually faster and still can find very good parameters, especially when the search space is large or includes distributions.
Reference
Scikit-Learn documentation on hyperparameter tuning: https://scikit-learn.org/stable/modules/grid_search.html#randomized-parameter-optimization
質問 # 45
Which of the following evaluation metrics is not suitable to evaluate runs in AutoML experiments for regression problems?
- A. R-squared
- B. F1
- C. MSE
- D. MAE
正解:B
解説:
The code block provided by the machine learning engineer will perform the desired inference when the Feature Store feature set was logged with the model at model_uri. This ensures that all necessary feature transformations and metadata are available for the model to make predictions. The Feature Store in Databricks allows for seamless integration of features and models, ensuring that the required features are correctly used during inference.
Reference:
Databricks documentation on Feature Store: Feature Store in Databricks
質問 # 46
A team is developing guidelines on when to use various evaluation metrics for classification problems. The team needs to provide input on when to use the F1 score over accuracy.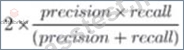
Which of the following suggestions should the team include in their guidelines?
- A. The F1 score should be utilized over accuracy when there are greater than two classes in the target variable.
- B. The F1 score should be utilized over accuracy when there is significant imbalance between positive and negative classes and avoiding false negatives is a priority.
- C. The F1 score should be utilized over accuracy when identifying true positives and true negatives are equally important to the business problem.
- D. The F1 score should be utilized over accuracy when the number of actual positive cases is identical to the number of actual negative cases.
正解:B
解説:
The F1 score is the harmonic mean of precision and recall and is particularly useful in situations where there is a significant imbalance between positive and negative classes. When there is a class imbalance, accuracy can be misleading because a model can achieve high accuracy by simply predicting the majority class. The F1 score, however, provides a better measure of the test's accuracy in terms of both false positives and false negatives.
Specifically, the F1 score should be used over accuracy when:
There is a significant imbalance between positive and negative classes.
Avoiding false negatives is a priority, meaning recall (the ability to detect all positive instances) is crucial.
In this scenario, the F1 score balances both precision (the ability to avoid false positives) and recall, providing a more meaningful measure of a model's performance under these conditions.
Reference:
Databricks documentation on classification metrics: Classification Metrics
質問 # 47
A data scientist wants to tune a set of hyperparameters for a machine learning model. They have wrapped a Spark ML model in the objective function objective_function and they have defined the search space search_space.
As a result, they have the following code block:
Which of the following changes do they need to make to the above code block in order to accomplish the task?
- A. Change fmin() to fmax()
- B. Change SparkTrials() to Trials()
- C. Remove the algo=tpe.suggest argument
- D. Remove the trials=trials argument
- E. Reduce num_evals to be less than 10
正解:B
解説:
The SparkTrials() is used to distribute trials of hyperparameter tuning across a Spark cluster. If the environment does not support Spark or if the user prefers not to use distributed computing for this purpose, switching to Trials() would be appropriate. Trials() is the standard class for managing search trials in Hyperopt but does not distribute the computation. If the user is encountering issues with SparkTrials() possibly due to an unsupported configuration or an error in the cluster setup, using Trials() can be a suitable change for running the optimization locally or in a non-distributed manner.
Reference
Hyperopt documentation: http://hyperopt.github.io/hyperopt/
質問 # 48
A data scientist has created a linear regression model that uses log(price) as a label variable. Using this model, they have performed inference and the predictions and actual label values are in Spark DataFrame preds_df.
They are using the following code block to evaluate the model:
regression_evaluator.setMetricName("rmse").evaluate(preds_df)
Which of the following changes should the data scientist make to evaluate the RMSE in a way that is comparable with price?
- A. They should exponentiate the computed RMSE value
- B. They should exponentiate the predictions before computing the RMSE
- C. They should take the log of the predictions before computing the RMSE
- D. They should evaluate the MSE of the log predictions to compute the RMSE
正解:B
解説:
When evaluating the RMSE for a model that predicts log-transformed prices, the predictions need to be transformed back to the original scale to obtain an RMSE that is comparable with the actual price values. This is done by exponentiating the predictions before computing the RMSE. The RMSE should be computed on the same scale as the original data to provide a meaningful measure of error.
Reference:
Databricks documentation on regression evaluation: Regression Evaluation
質問 # 49
Which statement describes a Spark ML transformer?
- A. A transformer is an algorithm which can transform one DataFrame into another DataFrame
- B. A transformer is a learning algorithm that can use a DataFrame to train a model
- C. A transformer chains multiple algorithms together to transform an ML workflow
- D. A transformer is a hyperparameter grid that can be used to train a model
正解:A
解説:
In Spark ML, a transformer is an algorithm that can transform one DataFrame into another DataFrame. It takes a DataFrame as input and produces a new DataFrame as output. This transformation can involve adding new columns, modifying existing ones, or applying feature transformations. Examples of transformers in Spark MLlib include feature transformers like StringIndexer, VectorAssembler, and StandardScaler.
Reference:
Databricks documentation on transformers: Transformers in Spark ML
質問 # 50
Which of the following tools can be used to distribute large-scale feature engineering without the use of a UDF or pandas Function API for machine learning pipelines?
- A. Scikit-learn
- B. Keras
- C. PyTorch
- D. Spark ML
正解:D
解説:
Spark MLlib is a machine learning library within Apache Spark that provides scalable and distributed machine learning algorithms. It is designed to work with Spark DataFrames and leverages Spark's distributed computing capabilities to perform large-scale feature engineering and model training without the need for user-defined functions (UDFs) or the pandas Function API. Spark MLlib provides built-in transformations and algorithms that can be applied directly to large datasets.
Reference:
Databricks documentation on Spark MLlib: Spark MLlib
質問 # 51
A machine learning engineer wants to parallelize the inference of group-specific models using the Pandas Function API. They have developed the apply_model function that will look up and load the correct model for each group, and they want to apply it to each group of DataFrame df.
They have written the following incomplete code block:
Which piece of code can be used to fill in the above blank to complete the task?
- A. predict
- B. applyInPandas
- C. groupedApplyInPandas
- D. mapInPandas
正解:B
解説:
To parallelize the inference of group-specific models using the Pandas Function API in PySpark, you can use the applyInPandas function. This function allows you to apply a Python function on each group of a DataFrame and return a DataFrame, leveraging the power of pandas UDFs (user-defined functions) for better performance.
prediction_df = ( df.groupby("device_id") .applyInPandas(apply_model, schema=apply_return_schema) ) In this code:
groupby("device_id"): Groups the DataFrame by the "device_id" column.
applyInPandas(apply_model, schema=apply_return_schema): Applies the apply_model function to each group and specifies the schema of the return DataFrame.
Reference:
PySpark Pandas UDFs Documentation
質問 # 52
A data scientist has been given an incomplete notebook from the data engineering team. The notebook uses a Spark DataFrame spark_df on which the data scientist needs to perform further feature engineering. Unfortunately, the data scientist has not yet learned the PySpark DataFrame API.
Which of the following blocks of code can the data scientist run to be able to use the pandas API on Spark?
- A. import pyspark.pandas as ps
df = ps.to_pandas(spark_df) - B. spark_df.to_pandas()
- C. import pandas as pd
df = pd.DataFrame(spark_df) - D. import pyspark.pandas as ps
df = ps.DataFrame(spark_df) - E. spark_df.to_sql()
正解:D
解説:
To use the pandas API on Spark, which is designed to bridge the gap between the simplicity of pandas and the scalability of Spark, the correct approach involves importing the pyspark.pandas (recently renamed to pandas_api_on_spark) module and converting a Spark DataFrame to a pandas-on-Spark DataFrame using this API. The provided syntax correctly initializes a pandas-on-Spark DataFrame, allowing the data scientist to work with the familiar pandas-like API on large datasets managed by Spark.
Reference
Pandas API on Spark Documentation: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/index.html
質問 # 53
......
更新されたPDF(2024年最新)実際にあるDatabricks Databricks-Machine-Learning-Associate試験問題:https://www.passtest.jp/Databricks/Databricks-Machine-Learning-Associate-shiken.html
問題集返金保証付きのDatabricks-Machine-Learning-Associate問題集公式問題集:https://drive.google.com/open?id=1hIkco9D1hSrhrqEV0cufHSBzJNHGfzMS