![]()
Databricks Databricks-Generative-AI-Engineer-Associateリアル試験問題解答は無料
試験問題集でDatabricks-Generative-AI-Engineer-Associate練習無料最新のDatabricks練習テスト
質問 # 26
A Generative AI Engineer is designing a RAG application for answering user questions on technical regulations as they learn a new sport.
What are the steps needed to build this RAG application and deploy it?
- A. User submits queries against an LLM -> Ingest documents from a source -> Index the documents and save to Vector Search -> LLM retrieves relevant documents -> LLM generates a response -> Evaluate model -> Deploy it using Model Serving
- B. Ingest documents from a source -> Index the documents and save to Vector Search -> User submits queries against an LLM -> LLM retrieves relevant documents -> LLM generates a response -> Evaluate model -> Deploy it using Model Serving
- C. Ingest documents from a source -> Index the documents and save to Vector Search -> Evaluate model -
> Deploy it using Model Serving - D. Ingest documents from a source -> Index the documents and saves to Vector Search -> User submits queries against an LLM -> LLM retrieves relevant documents -> Evaluate model -> LLM generates a response -> Deploy it using Model Serving
正解:B
解説:
The Generative AI Engineer needs to follow a methodical pipeline to build and deploy a Retrieval- Augmented Generation (RAG) application. The steps outlined in optionBaccurately reflect this process:
* Ingest documents from a source: This is the first step, where the engineer collects documents (e.g., technical regulations) that will be used for retrieval when the application answers user questions.
* Index the documents and save to Vector Search: Once the documents are ingested, they need to be embedded using a technique like embeddings (e.g., with a pre-trained model like BERT) and stored in a vector database (such as Pinecone or FAISS). This enables fast retrieval based on user queries.
* User submits queries against an LLM: Users interact with the application by submitting their queries.
These queries will be passed to the LLM.
* LLM retrieves relevant documents: The LLM works with the vector store to retrieve the most relevant documents based on their vector representations.
* LLM generates a response: Using the retrieved documents, the LLM generates a response that is tailored to the user's question.
* Evaluate model: After generating responses, the system must be evaluated to ensure the retrieved documents are relevant and the generated response is accurate. Metrics such as accuracy, relevance, and user satisfaction can be used for evaluation.
* Deploy it using Model Serving: Once the RAG pipeline is ready and evaluated, it is deployed using a model-serving platform such as Databricks Model Serving. This enables real-time inference and response generation for users.
By following these steps, the Generative AI Engineer ensures that the RAG application is both efficient and effective for the task of answering technical regulation questions.
質問 # 27
A Generative AI Engineer is designing a chatbot for a gaming company that aims to engage users on its platform while its users play online video games.
Which metric would help them increase user engagement and retention for their platform?
- A. Diversity of responses
- B. Randomness
- C. Repetition of responses
- D. Lack of relevance
正解:A
解説:
In the context of designing a chatbot to engage users on a gaming platform,diversity of responses(option B) is a key metric to increase user engagement and retention. Here's why:
* Diverse and Engaging Interactions:A chatbot that provides varied and interesting responses will keep users engaged, especially in an interactive environment like a gaming platform. Gamers typically enjoy dynamic and evolving conversations, anddiversity of responseshelps prevent monotony, encouraging users to interact more frequently with the bot.
* Increasing Retention:By offering different types of responses to similar queries, the chatbot can create a sense of novelty and excitement, which enhances the user's experience and makes them more likely to return to the platform.
* Why Other Options Are Less Effective:
* A (Randomness): Random responses can be confusing or irrelevant, leading to frustration and reducing engagement.
* C (Lack of Relevance): If responses are not relevant to the user's queries, this will degrade the user experience and lead to disengagement.
* D (Repetition of Responses): Repetitive responses can quickly bore users, making the chatbot feel uninteresting and reducing the likelihood of continued interaction.
Thus,diversity of responses(option B) is the most effective way to keep users engaged and retain them on the platform.
質問 # 28
A Generative AI Engineer has a provisioned throughput model serving endpoint as part of a RAG application and would like to monitor the serving endpoint's incoming requests and outgoing responses. The current approach is to include a micro-service in between the endpoint and the user interface to write logs to a remote server.
Which Databricks feature should they use instead which will perform the same task?
- A. Inference Tables
- B. DBSQL
- C. Lakeview
- D. Vector Search
正解:A
解説:
Problem Context: The goal is to monitor theserving endpointfor incoming requests and outgoing responses in aprovisioned throughput model serving endpointwithin aRetrieval-Augmented Generation (RAG) application. The current approach involves using a microservice to log requests and responses to a remote server, but the Generative AI Engineer is looking for a more streamlined solution within Databricks.
Explanation of Options:
* Option A: Vector Search: This feature is used to perform similarity searches within vector databases.
It doesn't provide functionality for logging or monitoring requests and responses in a serving endpoint, so it's not applicable here.
* Option B: Lakeview: Lakeview is not a feature relevant to monitoring or logging request-response cycles for serving endpoints. It might be more related to viewing data in Databricks Lakehouse but doesn't fulfill the specific monitoring requirement.
* Option C: DBSQL: Databricks SQL (DBSQL) is used for running SQL queries on data stored in Databricks, primarily for analytics purposes. It doesn't provide the direct functionality needed to monitor requests and responses in real-time for an inference endpoint.
* Option D: Inference Tables: This is the correct answer.Inference Tablesin Databricks are designed to store the results and metadata of inference runs. This allows the system to logincoming requests and outgoing responsesdirectly within Databricks, making it an ideal choice for monitoring the behavior of a provisioned serving endpoint. Inference Tables can be queried and analyzed, enabling easier monitoring and debugging compared to a custom microservice.
Thus,Inference Tablesare the optimal feature for monitoring request and response logs within the Databricks infrastructure for a model serving endpoint.
質問 # 29
A company has a typical RAG-enabled, customer-facing chatbot on its website.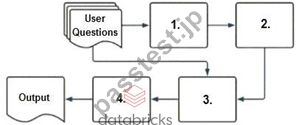
Select the correct sequence of components a user's questions will go through before the final output is returned. Use the diagram above for reference.
- A. 1.response-generating LLM, 2.vector search, 3.context-augmented prompt, 4.embedding model
- B. 1.response-generating LLM, 2.context-augmented prompt, 3.vector search, 4.embedding model
- C. 1.embedding model, 2.vector search, 3.context-augmented prompt, 4.response-generating LLM
- D. 1.context-augmented prompt, 2.vector search, 3.embedding model, 4.response-generating LLM
正解:C
解説:
To understand how a typical RAG-enabled customer-facing chatbot processes a user's question, let's go through the correct sequence as depicted in the diagram and explained in option A:
* Embedding Model (1):The first step involves the user's question being processed through an embedding model. This model converts the text into a vector format that numerically represents the text. This step is essential for allowing the subsequent vector search to operate effectively.
* Vector Search (2):The vectors generated by the embedding model are then used in a vector search mechanism. This search identifies the most relevant documents or previously answered questions that are stored in a vector format in a database.
* Context-Augmented Prompt (3):The information retrieved from the vector search is used to create a context-augmented prompt. This step involves enhancing the basic user query with additional relevant information gathered to ensure the generated response is as accurate and informative as possible.
* Response-Generating LLM (4):Finally, the context-augmented prompt is fed into a response- generating large language model (LLM). This LLM uses the prompt to generate a coherent and contextually appropriate answer, which is then delivered as the final output to the user.
Why Other Options Are Less Suitable:
* B, C, D: These options suggest incorrect sequences that do not align with how a RAG system typically processes queries. They misplace the role of embedding models, vector search, and response generation in an order that would not facilitate effective information retrieval and response generation.
Thus, the correct sequence isembedding model, vector search, context-augmented prompt, response- generating LLM, which is option A.
質問 # 30
A Generative AI Engineer I using the code below to test setting up a vector store:
Assuming they intend to use Databricks managed embeddings with the default embedding model, what should be the next logical function call?
- A. vsc.create_delta_sync_index()
- B. vsc.create_direct_access_index()
- C. vsc.similarity_search()
- D. vsc.get_index()
正解:A
解説:
Context: The Generative AI Engineer is setting up a vector store using Databricks' VectorSearchClient. This is typically done to enable fast and efficient retrieval of vectorized data for tasks like similarity searches.
Explanation of Options:
* Option A: vsc.get_index(): This function would be used to retrieve an existing index, not create one, so it would not be the logical next step immediately after creating an endpoint.
* Option B: vsc.create_delta_sync_index(): After setting up a vector store endpoint, creating an index is necessary to start populating and organizing the data. The create_delta_sync_index() function specifically creates an index that synchronizes with a Delta table, allowing automatic updates as the data changes. This is likely the most appropriate choice if the engineer plans to use dynamic data that is updated over time.
* Option C: vsc.create_direct_access_index(): This function would create an index that directly accesses the data without synchronization. While also a valid approach, it's less likely to be the next logical step if the default setup (typically accommodating changes) is intended.
* Option D: vsc.similarity_search(): This function would be used to perform searches on an existing index; however, an index needs to be created and populated with data before any search can be conducted.
Given the typical workflow in setting up a vector store, the next step after creating an endpoint is to establish an index, particularly one that synchronizes with ongoing data updates, henceOption B.
質問 # 31
A Generative Al Engineer has developed an LLM application to answer questions about internal company policies. The Generative AI Engineer must ensure that the application doesn't hallucinate or leak confidential data.
Which approach should NOT be used to mitigate hallucination or confidential data leakage?
- A. Add guardrails to filter outputs from the LLM before it is shown to the user
- B. Limit the data available based on the user's access level
- C. Use a strong system prompt to ensure the model aligns with your needs.
- D. Fine-tune the model on your data, hoping it will learn what is appropriate and not
正解:D
解説:
When addressing concerns of hallucination and data leakage in an LLM application for internal company policies, fine-tuning the model on internal data with the hope it learns data boundaries can be problematic:
* Risk of Data Leakage: Fine-tuning on sensitive or confidential data does not guarantee that the model will not inadvertently include or reference this data in its outputs. There's a risk of overfitting to the specific data details, which might lead to unintended leakage.
* Hallucination: Fine-tuning does not necessarily mitigate the model's tendency to hallucinate; in fact, it might exacerbate it if the training data is not comprehensive or representative of all potential queries.
Better Approaches:
* A,C, andDinvolve setting up operational safeguards and constraints that directly address data leakage and ensure responses are aligned with specific user needs and security levels.
Fine-tuning lacks the targeted control needed for such sensitive applications and can introduce new risks, making it an unsuitable approach in this context.
質問 # 32
What is the most suitable library for building a multi-step LLM-based workflow?
- A. Pandas
- B. PySpark
- C. TensorFlow
- D. LangChain
正解:D
解説:
* Problem Context: The Generative AI Engineer needs a tool to build amulti-step LLM-based workflow. This type of workflow often involves chaining multiple steps together, such as query generation, retrieval of information, response generation, and post-processing, with LLMs integrated at several points.
* Explanation of Options:
* Option A: Pandas: Pandas is a powerful data manipulation library for structured data analysis, but it is not designed for managing or orchestrating multi-step workflows, especially those involving LLMs.
* Option B: TensorFlow: TensorFlow is primarily used for training and deploying machine learning models, especially deep learning models. It is not designed for orchestrating multi-step tasks in LLM-based workflows.
* Option C: PySpark: PySpark is a distributed computing framework used for large-scale data processing. While useful for handling big data, it is not specialized for chaining LLM-based operations.
* Option D: LangChain: LangChain is a purpose-built framework designed specifically for orchestrating multi-step workflowswith large language models (LLMs). It enables developers to easily chain different tasks, such as retrieving documents, summarizing information, and generating responses, all in a structured flow. This makes it the best tool for building complex LLM-based workflows.
Thus,LangChainis the most suitable library for creating multi-step LLM-based workflows.
質問 # 33
Which indicator should be considered to evaluate the safety of the LLM outputs when qualitatively assessing LLM responses for a translation use case?
- A. The ability to generate responses in code
- B. The accuracy and relevance of the responses
- C. The latency of the response and the length of text generated
- D. The similarity to the previous language
正解:B
解説:
* Problem Context: When assessing the safety and effectiveness of LLM outputs in a translation use case, it is essential to ensure that the translations accurately and relevantly convey the intended message. The evaluation should focus on how well the LLM understands and processes different languages and contexts.
* Explanation of Options:
* Option A: The ability to generate responses in code- This is not relevant to translation quality or safety.
* Option B: The similarity to the previous language- While ensuring that translations preserve the original's intent is important, this doesn't directly address the overall quality or safety of the translation.
* Option C: The latency of the response and the length of text generated- These operational metrics are less critical in assessing the qualitative aspects of translation safety.
* Option D: The accuracy and relevance of the responses- This is crucial in translation to ensure that the translated content is true to the original in meaning and appropriateness. Accuracy and relevance directly impact the effectiveness and safety of translations, especially in sensitive or nuanced contexts.
Thus,Option Dis the most important indicator when evaluating the safety of LLM outputs in translation, focusing on the core aspects that determine the utility and trustworthiness of translated content.
質問 # 34
A Generative Al Engineer is creating an LLM-based application. The documents for its retriever have been chunked to a maximum of 512 tokens each. The Generative Al Engineer knows that cost and latency are more important than quality for this application. They have several context length levels to choose from.
Which will fulfill their need?
- A. context length 2048: smallest model is 11GB and embedding dimension 2560
- B. context length 32768: smallest model is 14GB and embedding dimension 4096
- C. context length 512: smallest model is 0.13GB and embedding dimension 384
- D. context length 514; smallest model is 0.44GB and embedding dimension 768
正解:C
解説:
When prioritizing cost and latency over quality in a Large Language Model (LLM)-based application, it is crucial to select a configuration that minimizes both computational resources and latency while still providing reasonable performance. Here's whyDis the best choice:
* Context length: The context length of 512 tokens aligns with the chunk size used for the documents (maximum of 512 tokens per chunk). This is sufficient for capturing the needed information and generating responses without unnecessary overhead.
* Smallest model size: The model with a size of 0.13GB is significantly smaller than the other options.
This small footprint ensures faster inference times and lower memory usage, which directly reduces both latency and cost.
* Embedding dimension: While the embedding dimension of 384 is smaller than the other options, it is still adequate for tasks where cost and speed are more important than precision and depth of understanding.
This setup achieves the desired balance between cost-efficiency and reasonable performance in a latency- sensitive, cost-conscious application.
質問 # 35
A Generative AI Engineer developed an LLM application using the provisioned throughput Foundation Model API. Now that the application is ready to be deployed, they realize their volume of requests are not sufficiently high enough to create their own provisioned throughput endpoint. They want to choose a strategy that ensures the best cost-effectiveness for their application.
What strategy should the Generative AI Engineer use?
- A. Switch to using External Models instead
- B. Throttle the incoming batch of requests manually to avoid rate limiting issues
- C. Change to a model with a fewer number of parameters in order to reduce hardware constraint issues
- D. Deploy the model using pay-per-token throughput as it comes with cost guarantees
正解:D
解説:
* Problem Context: The engineer needs a cost-effective deployment strategy for an LLM application with relatively low request volume.
* Explanation of Options:
* Option A: Switching to external models may not provide the required control or integration necessary for specific application needs.
* Option B: Using a pay-per-token model is cost-effective, especially for applications with variable or low request volumes, as it aligns costs directly with usage.
* Option C: Changing to a model with fewer parameters could reduce costs, but might also impact the performance and capabilities of the application.
* Option D: Manually throttling requests is a less efficient and potentially error-prone strategy for managing costs.
OptionBis ideal, offering flexibility and cost control, aligning expenses directly with the application's usage patterns.
質問 # 36
A Generative AI Engineer is building a Generative AI system that suggests the best matched employee team member to newly scoped projects. The team member is selected from a very large team. Thematch should be based upon project date availability and how well their employee profile matches the project scope. Both the employee profile and project scope are unstructured text.
How should the Generative Al Engineer architect their system?
- A. Create a tool to find available team members given project dates. Create a second tool that can calculate a similarity score for a combination of team member profile and the project scope. Iterate through the team members and rank by best score to select a team member.
- B. Create a tool for finding team member availability given project dates, and another tool that uses an LLM to extract keywords from project scopes. Iterate through available team members' profiles and perform keyword matching to find the best available team member.
- C. Create a tool for finding available team members given project dates. Embed team profiles into a vector store and use the project scope and filtering to perform retrieval to find the available best matched team members.
- D. Create a tool for finding available team members given project dates. Embed all project scopes into a vector store, perform a retrieval using team member profiles to find the best team member.
正解:C
解説:
* Problem Context: The problem involves matching team members to new projects based on two main factors:
* Availability: Ensure the team members are available during the project dates.
* Profile-Project Match: Use the employee profiles (unstructured text) to find the best match for a project's scope (also unstructured text).
The two main inputs are theemployee profilesandproject scopes, both of which are unstructured. This means traditional rule-based systems (e.g., simple keyword matching) would be inefficient, especially when working with large datasets.
* Explanation of Options: Let's break down the provided options to understand why D is the most optimal answer.
* Option Asuggests embedding project scopes into a vector store and then performing retrieval using team member profiles. While embedding project scopes into a vector store is a valid technique, it skips an important detail: the focus should primarily be on embedding employee profiles because we're matching the profiles to a new project, not the other way around.
* Option Binvolves using a large language model (LLM) to extract keywords from the project scope and perform keyword matching on employee profiles. While LLMs can help with keyword extraction, this approach is too simplistic and doesn't leverage advanced retrieval techniques like vector embeddings, which can handle the nuanced and rich semantics of unstructured data. This approach may miss out on subtle but important similarities.
* Option Csuggests calculating a similarity score between each team member's profile and project scope. While this is a good idea, it doesn't specify how to handle the unstructured nature of data efficiently. Iterating through each member's profile individually could be computationally expensive in large teams. It also lacks the mention of using a vector store or an efficient retrieval mechanism.
* Option Dis the correct approach. Here's why:
* Embedding team profiles into a vector store: Using a vector store allows for efficient similarity searches on unstructured data. Embedding the team member profiles into vectors captures their semantics in a way that is far more flexible than keyword-based matching.
* Using project scope for retrieval: Instead of matching keywords, this approach suggests using vector embeddings and similarity search algorithms (e.g., cosine similarity) to find the team members whose profiles most closely align with the project scope.
* Filtering based on availability: Once the best-matched candidates are retrieved based on profile similarity, filtering them by availability ensures that the system provides a practically useful result.
This method efficiently handles large-scale datasets by leveragingvector embeddingsandsimilarity search techniques, both of which are fundamental tools inGenerative AI engineeringfor handling unstructured text.
* Technical References:
* Vector embeddings: In this approach, the unstructured text (employee profiles and project scopes) is converted into high-dimensional vectors using pretrained models (e.g., BERT, Sentence-BERT, or custom embeddings). These embeddings capture the semantic meaning of the text, making it easier to perform similarity-based retrieval.
* Vector stores: Solutions likeFAISSorMilvusallow storing and retrieving large numbers of vector embeddings quickly. This is critical when working with large teams where querying through individual profiles sequentially would be inefficient.
* LLM Integration: Large language models can assist in generating embeddings for both employee profiles and project scopes. They can also assist in fine-tuning similarity measures, ensuring that the retrieval system captures the nuances of the text data.
* Filtering: After retrieving the most similar profiles based on the project scope, filtering based on availability ensures that only team members who are free for the project are considered.
This system is scalable, efficient, and makes use of the latest techniques inGenerative AI, such as vector embeddings and semantic search.
質問 # 37
A Generative Al Engineer has already trained an LLM on Databricks and it is now ready to be deployed.
Which of the following steps correctly outlines the easiest process for deploying a model on Databricks?
- A. Log the model using MLflow during training, directly register the model to Unity Catalog using the MLflow API, and start a serving endpoint
- B. Log the model as a pickle object, upload the object to Unity Catalog Volume, register it to Unity Catalog using MLflow, and start a serving endpoint
- C. Wrap the LLM's prediction function into a Flask application and serve using Gunicorn
- D. Save the model along with its dependencies in a local directory, build the Docker image, and run the Docker container
正解:A
解説:
* Problem Context: The goal is to deploy a trained LLM on Databricks in the simplest and most integrated manner.
* Explanation of Options:
* Option A: This method involves unnecessary steps like logging the model as a pickle object, which is not the most efficient path in a Databricks environment.
* Option B: Logging the model with MLflow during training and then using MLflow's API to register and start serving the model is straightforward and leverages Databricks' built-in functionalities for seamless model deployment.
* Option C: Building and running a Docker container is a complex and less integrated approach within the Databricks ecosystem.
* Option D: Using Flask and Gunicorn is a more manual approach and less integrated compared to the native capabilities of Databricks and MLflow.
OptionBprovides the most straightforward and efficient process, utilizing Databricks' ecosystem to its full advantage for deploying models.
質問 # 38
A Generative AI Engineer is designing an LLM-powered live sports commentary platform. The platform provides real-time updates and LLM-generated analyses for any users who would like to have live summaries, rather than reading a series of potentially outdated news articles.
Which tool below will give the platform access to real-time data for generating game analyses based on the latest game scores?
- A. DatabrickslQ
- B. AutoML
- C. Foundation Model APIs
- D. Feature Serving
正解:D
解説:
* Problem Context: The engineer is developing an LLM-powered live sports commentary platform that needs to provide real-time updates and analyses based on the latest game scores. The critical requirement here is the capability to access and integrate real-time data efficiently with the platform for immediate analysis and reporting.
* Explanation of Options:
* Option A: DatabricksIQ: While DatabricksIQ offers integration and data processing capabilities, it is more aligned with data analytics rather than real-time feature serving, which is crucial for immediate updates necessary in a live sports commentary context.
* Option B: Foundation Model APIs: These APIs facilitate interactions with pre-trained models and could be part of the solution, but on their own, they do not provide mechanisms to access real- time game scores.
* Option C: Feature Serving: This is the correct answer as feature serving specifically refers to the real-time provision of data (features) to models for prediction. This would be essential for an LLM that generates analyses based on live game data, ensuring that the commentary is current and based on the latest events in the sport.
* Option D: AutoML: This tool automates the process of applying machine learning models to real-world problems, but it does not directly provide real-time data access, which is a critical requirement for the platform.
Thus,Option C(Feature Serving) is the most suitable tool for the platform as it directly supports the real-time data needs of an LLM-powered sports commentary system, ensuring that the analyses and updates are based on the latest available information.
質問 # 39
A Generative AI Engineer has been asked to build an LLM-based question-answering application. The application should take into account new documents that are frequently published. The engineer wants to build this application with the least cost and least development effort and have it operate at the lowest cost possible.
Which combination of chaining components and configuration meets these requirements?
- A. For the application a prompt, an agent and a fine-tuned LLM are required. The agent is used by the LLM to retrieve relevant content that is inserted into the prompt which is given to the LLM to generate answers.
- B. The LLM needs to be frequently with the new documents in order to provide most up-to-date answers.
- C. For the application a prompt, a retriever, and an LLM are required. The retriever output is inserted into the prompt which is given to the LLM to generate answers.
- D. For the question-answering application, prompt engineering and an LLM are required to generate answers.
正解:C
解説:
Problem Context: The task is to build an LLM-based question-answering application that integrates new documents frequently with minimal costs and development efforts.
Explanation of Options:
* Option A: Utilizes a prompt and a retriever, with the retriever output being fed into the LLM. This setup is efficient because it dynamically updates the data pool via the retriever, allowing the LLM to provide up-to-date answers based on the latest documents without needing tofrequently retrain the model. This method offers a balance of cost-effectiveness and functionality.
* Option B: Requires frequent retraining of the LLM, which is costly and labor-intensive.
* Option C: Only involves prompt engineering and an LLM, which may not adequately handle the requirement for incorporating new documents unless it's part of an ongoing retraining or updating mechanism, which would increase costs.
* Option D: Involves an agent and a fine-tuned LLM, which could be overkill and lead to higher development and operational costs.
Option Ais the most suitable as it provides a cost-effective, minimal development approach while ensuring the application remains up-to-date with new information.
質問 # 40
A Generative Al Engineer is building a system which will answer questions on latest stock news articles.
Which will NOT help with ensuring the outputs are relevant to financial news?
- A. Increase the compute to improve processing speed of questions to allow greater relevancy analysis C Implement a profanity filter to screen out offensive language
- B. Implement a comprehensive guardrail framework that includes policies for content filters tailored to the finance sector.
- C. Incorporate manual reviews to correct any problematic outputs prior to sending to the users
正解:A
解説:
In the context of ensuring that outputs are relevant to financial news, increasing compute power (option B) does not directly improve therelevanceof the LLM-generated outputs. Here's why:
* Compute Power and Relevancy:Increasing compute power can help the model process inputs faster, but it does not inherentlyimprove therelevanceof the answers. Relevancy depends on the data sources, the retrieval method, and the filtering mechanisms in place, not on how quickly the model processes the query.
* What Actually Helps with Relevance:Other methods, like content filtering, guardrails, or manual review, can directly impact the relevance of the model's responses by ensuring the model focuses on pertinent financial content. These methods help tailor the LLM's responses to the financial domain and avoid irrelevant or harmful outputs.
* Why Other Options Are More Relevant:
* A (Comprehensive Guardrail Framework): This will ensure that the model avoids generating content that is irrelevant or inappropriate in the finance sector.
* C (Profanity Filter): While not directly related to financial relevancy, ensuring the output is clean and professional is still important in maintaining the quality of responses.
* D (Manual Review): Incorporating human oversight to catch and correct issues with the LLM's output ensures the final answers are aligned with financial content expectations.
Thus, increasing compute power does not help with ensuring the outputs are more relevant to financial news, making option B the correct answer.
質問 # 41
A team wants to serve a code generation model as an assistant for their software developers. It should support multiple programming languages. Quality is the primary objective.
Which of the Databricks Foundation Model APIs, or models available in the Marketplace, would be the best fit?
- A. CodeLlama-34B
- B. Llama2-70b
- C. BGE-large
- D. MPT-7b
正解:A
解説:
For a code generation model that supports multiple programming languages and where quality is the primary objective,CodeLlama-34Bis the most suitable choice. Here's the reasoning:
* Specialization in Code Generation:CodeLlama-34B is specifically designed for code generation tasks.
This model has been trained with a focus on understanding and generating code, which makes it particularly adept at handling various programming languages and coding contexts.
* Capacity and Performance:The "34B" indicates a model size of 34 billion parameters, suggesting a high capacity for handling complex tasks and generating high-quality outputs. The large model size typically correlates with better understanding and generation capabilities in diverse scenarios.
* Suitability for Development Teams:Given that the model is optimized for code, it will be able to assist software developers more effectively than general-purpose models. It understands coding syntax, semantics, and the nuances of different programming languages.
* Why Other Options Are Less Suitable:
* A (Llama2-70b): While also a large model, it's more general-purpose and may not be as fine- tuned for code generation as CodeLlama.
* B (BGE-large): This model may not specifically focus on code generation.
* C (MPT-7b): Smaller than CodeLlama-34B and likely less capable in handling complex code generation tasks at high quality.
Therefore, for a high-quality, multi-language code generation application,CodeLlama-34B(option D) is the best fit.
質問 # 42
A Generative AI Engineer is developing an LLM application that users can use to generate personalized birthday poems based on their names.
Which technique would be most effective in safeguarding the application, given the potential for malicious user inputs?
- A. Reduce the time that the users can interact with the LLM
- B. Ask the LLM to remind the user that the input is malicious but continue the conversation with the user
- C. Increase the amount of compute that powers the LLM to process input faster
- D. Implement a safety filter that detects any harmful inputs and ask the LLM to respond that it is unable to assist
正解:D
解説:
In this case, the Generative AI Engineer is developing an application to generate personalized birthday poems, but there's a need to safeguard againstmalicious user inputs. The best solution is to implement asafety filter (option A) to detect harmful or inappropriate inputs.
* Safety Filter Implementation:Safety filters are essential for screening user input and preventing inappropriate content from being processed by the LLM. These filters can scan inputs for harmful language, offensive terms, or malicious content and intervene before the prompt is passed to the LLM.
* Graceful Handling of Harmful Inputs:Once the safety filter detects harmful content, the system can provide a message to the user, such as "I'm unable to assist with this request," instead of processing or responding to malicious input. This protects the system from generating harmful content and ensures a controlled interaction environment.
* Why Other Options Are Less Suitable:
* B (Reduce Interaction Time): Reducing the interaction time won't prevent malicious inputs from being entered.
* C (Continue the Conversation): While it's possible to acknowledge malicious input, it is not safe to continue the conversation with harmful content. This could lead to legal or reputational risks.
* D (Increase Compute Power): Adding more compute doesn't address the issue of harmful content and would only speed up processing without resolving safety concerns.
Therefore, implementing asafety filterthat blocks harmful inputs is the most effective technique for safeguarding the application.
質問 # 43
......
確認済みDatabricks-Generative-AI-Engineer-Associate試験問題集と解答で時間限定無料提供!Databricks-Generative-AI-Engineer-Associateには正解付き:https://www.passtest.jp/Databricks/Databricks-Generative-AI-Engineer-Associate-shiken.html
Databricks-Generative-AI-Engineer-Associate試験問題、リアルDatabricks-Generative-AI-Engineer-Associate練習問題集:https://drive.google.com/open?id=1MEeQhvr76ySXb0qoNX9PYkAGZGr-qYfg